
Simple Guide on FLOPs in GPU Utilisation
FLOPs is a core measure of a GPU’s computation power. Higher the number of FLOPs a GPU has, it means the GPU can do more number of matrix operation per second. Currently, there’s a battle going on between companies on two fronts:
- Deliver GPU with more FLOPs
- Build models which don’t need a lot of computation
Not sure who’ll win, meanwhile let’s understand this concept in detail.
Table of Contents
What Are FLOPs?
A FLOP is a single arithmetic operation on floating-point numbers:
- Addition:
a + b= 1 FLOP - Multiplication:
a × b= 1 FLOP - Multiply-Add:
a × b + c= 2 FLOPs (1 multiply + 1 add)
FLOPS = Floating Point Operations Per Second measures the computational throughput. Lets compare some of the most powerful GPU available in the market today:
NVIDIA GPU Performance
┌─────────────────┬────────────────┬────────────────┬────────────────┐
│ GPU │ FP32 (TFLOPS) │ FP16 (TFLOPS) │ INT8 (TOPS) │
├─────────────────┼────────────────┼────────────────┼────────────────┤
│ NVIDIA A100 │ 19.5 │ 312 │ 624 │
│ NVIDIA H100 │ 67 │ 989 │ 1979 │
│ NVIDIA V100 │ 15.7 │ 125 │ - │
│ NVIDIA T4 │ 8.1 │ 65 │ 130 │
│ Apple M2 Ultra │ 27 │ - │ - │
└─────────────────┴────────────────┴────────────────┴────────────────┘
As you can see, quantization (or lower precision) leads to higher FLOPs.
We also learn that:
- FP16 is 16x faster than FP32 on A100
- INT8 is 32x faster than FP32
That’s why we quantization is helpful in inference because the GPU is able to run computations faster, hence leading to a lower TTFT.
What does FLOPs tell us about GPUs?
FLOPs doesn’t just tell the hardware specification of the GPU. Instead, it conveys that theoritical maximum limit to expect.
Let’s understand using an example. Here we are trying to compute the attention weights using some sample inputs:
# Q @ K^T in attention
batch_size = 32
seq_len = 2048
hidden_dim = 4096 # (no. of heads * head_dim)
# Matrix dimensions
Q= [32, 2048, 4096]
K= [32, 2048, 4096]
# Result: [32, 2048, 2048]
FLOPs = batch × seq_len × seq_len × hidden_dim × 2
= 32 × 2048 × 2048 × 4096 × 2
= 1.1 trillion FLOPs
# On A100 (312 TFLOPS in FP16):
Time = 1.1T FLOPs / 312 TFLOPS = 3.5 milliseconds (theoretical minimum)
This is our lower bound speed limit. It means we can do 1.1TFLOPS operations in 3.5 ms on a hardware which supports 312TFLOPS, assuming there 100% hardware utilisation, no I/O overhead.
Now, let’s try to convert FLOPS into cost terms. How much cost it would take to run a large LLM inference service at scale:
Lets make some assumptions:
- 10 million requests/day
- Average response: 100 tokens
- FLOPs per token (70B model : 2 operations): ~140 billion FLOPs
Daily FLOPs:
= 10M requests × 100 tokens × 140B FLOPs
= 1.4 × 10^20 FLOPs per day
= 140 exaFLOPs per day (exa = 1B * 1B)
GPU hours needed (A100 @ 312 TFLOPS):
= 1.4 × 10^20 / (312 × 10^12 × 3600)
= 124.6 GPU-hours per day
= 5.2 GPUs
Cost (A100 @ $2.50/hour):
= 124.6 × $2.50 = $312 per day
= $9.4k per month
Knowing how many FLOPs our hardware support, it is possible to estimate costs upfront. Ofcourse, the actual cost will be higher, because our calculations doesn’t consider overhead costs (KV cache, I/O, memory bound operations etc).
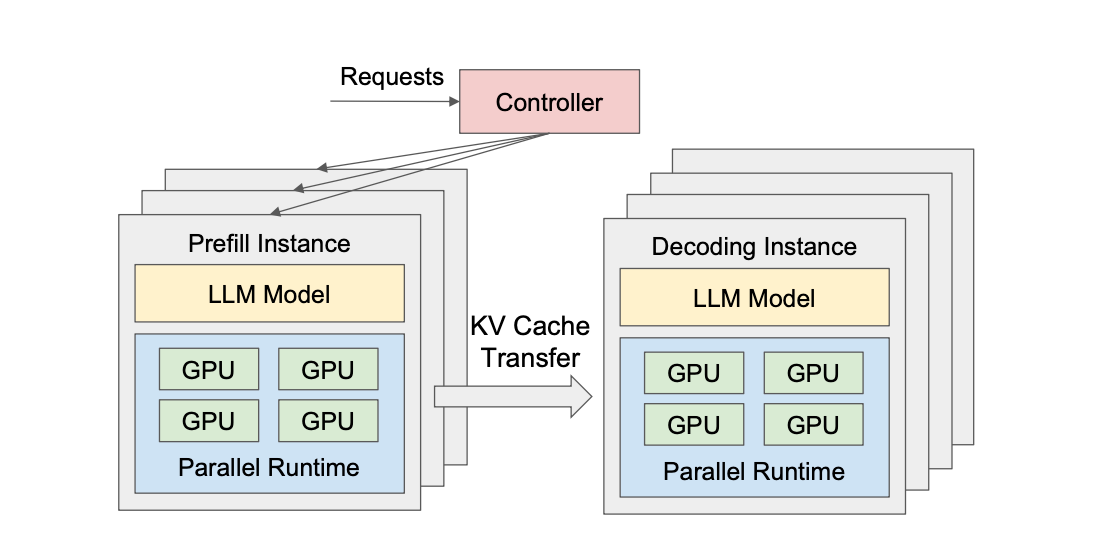
Role of FLOPs in Serving LLMs
When serving LLMs, inference happens in two distinct phases: Prefill and Decode. These phases have dramatically different FLOP characteristics, which fundamentally affects how we scale LLM serving systems.
Prefill is the phase where the model processes the entire input prompt at once. All input tokens are processed in parallel through the transformer layers. FLOPs in prefill stage undergo quadratic complexity computation.
Prefill stage is known for:
- High parallelism: All tokens are computed simultaneously
- Compute-bound: GPU cores are busy doing matrix multiplications
Decode is the phase where the model generates output one token at a time. This is also known as autoregressive generation where each new token depends on all previous tokens.
Decode stage is known for:
- Low parallelism: Only 1 token generated per step
- Memory-bound: Constantly reading KV cache from memory
- Slow: Sequential process, can’t be parallelized
During decode, the GPU spends most time reading the KV cache from memory:
# Observe the difference in memory vs compute bandwith
A100 GPU specs:
- Compute: 312 TFLOPS (FP16)
- Memory bandwidth: 2 TB/s
Decode bottleneck analysis:
- FLOPs needed: ~140 billion per token
- Memory reads: KV cache for 2048 tokens × 80 layers × 8192 hidden
= ~2.6 GB per token!
Time breakdown:
- Compute time: 140B FLOPs / 312 TFLOPS = 0.45ms
- Memory time: 2.6 GB / 2 TB/s = 1.3ms
Bottleneck: Memory (1.3ms) > Compute (0.45ms)
MFU = 0.45ms / 1.3ms = 35% (GPU is idle 65% of the time!)
This is why decode is memory-bound The GPU spends most time waiting for memory, not computing.
Now we know, Prefill is fast but compute-intensive (O(N²) FLOPs). Decode is slow and memory-bound, consuming 95%+ of inference time.
Understanding this asymmetry is crucial—optimize prefill for latency (add GPUs), optimize decode for throughput (increase batch size).
Your cost optimization strategy depends on which phase dominates your workload.
Summary
In this post, we learnt about the role of FLOPs in GPU hardware performance. FLOPs not only dictate the theoritical maximum of the hardware performance but also help us plan our resources well.
Do you also use FLOPs in order to estimate the hardware requirements? I am keen to hear your thoughts in the comments below.

Comments