
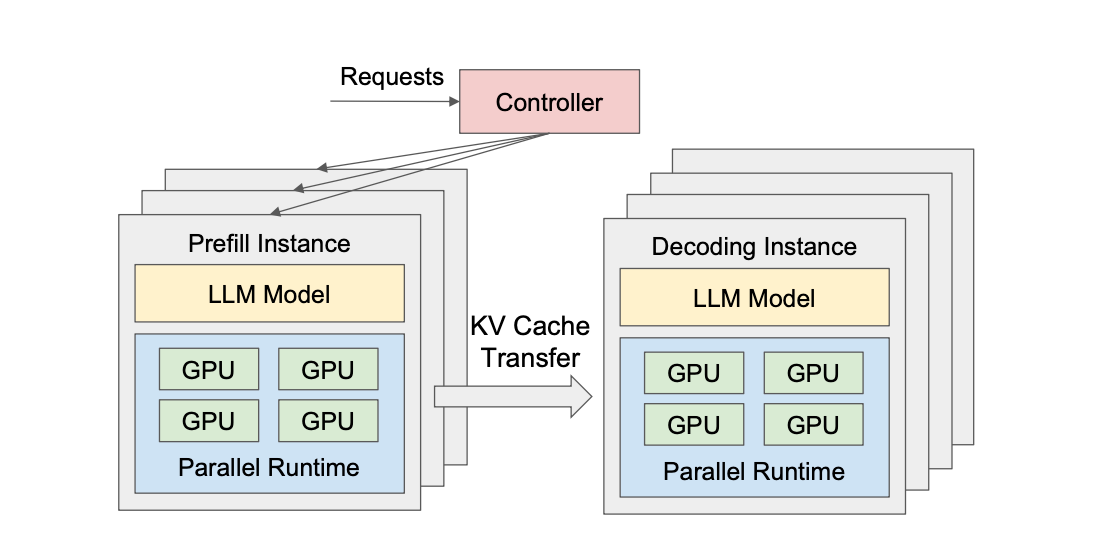
How to Build Multi-Objective Ranking Models with LightGBM
So here’s a question that probably seems obvious at first: if you’re building a search engine or a recommendation system, shouldn’t you just predict how good each result is and sort by that score?
That’s what everyone thinks. And it’s wrong. Not like “technically wrong but works okay” wrong, like fundamentally missing the entire point wrong.
Here’s the thing: ranking isn’t about predicting absolute scores. It’s about predicting relative order.
Table of Contents
- The Thing Everyone Gets Wrong About Ranking
- Why Pairwise Beats Pointwise Every Time
- The Math That Makes LambdaRank Actually Work
- Multi-Objective Ranking: When You Want Everything
- The Hessian Secret Weapon
- Making It Real: Query Groups and Implementation
- Running the Code Yourself
The Thing Everyone Gets Wrong About Ranking
Let’s say you’re building a search engine. Someone searches for “best pizza near me” and you have five restaurants to rank. The obvious approach called pointwise ranking goes like this:
- train a model to predict a relevance score for each restaurant (maybe 0 to 5 stars)
- then sort by those predictions.
Seems reasonable! Train a regression model, predict ratings, sort, done.
But think, there is a problem.
The pointwise approach treats each item independently. It learns to predict absolute scores. But ranking doesn’t care about absolute scores, it cares about which item should come first when you compare them head-to-head.
And that’s where pairwise ranking enters the chat.
Instead of training your model to predict “Restaurant A is 4.2 stars” and “Restaurant B is 4.1 stars,” you train it to answer a much simpler question: “Between A and B, which should rank higher?”
This is what LightGBM’s pairwise ranking objectives do. And it turns out this seemingly small shift changes everything as shown below:
Predict: 4.2 stars"] P2["Restaurant B
Predict: 4.1 stars"] P3["Restaurant C
Predict: 3.9 stars"] P1 -.-> P_SORT["Sort by
predicted scores"] P2 -.-> P_SORT P3 -.-> P_SORT P_SORT --> P_RESULT["Ranking: A, B, C
May be wrong if
predictions biased"] end subgraph Pairwise["Pairwise - Compares pairs"] Q1["A vs B:
Is A > B?"] Q2["A vs C:
Is A > C?"] Q3["B vs C:
Is B > C?"] Q1 --> Q_LEARN["Learn to order
pairs correctly"] Q2 --> Q_LEARN Q3 --> Q_LEARN Q_LEARN --> Q_RESULT["Ranking: A, B, C
Optimizes relative
order directly"] end style P1 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style P2 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style P3 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style P_SORT fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style P_RESULT fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style Q1 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style Q2 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style Q3 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style Q_LEARN fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style Q_RESULT fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style Pointwise fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px style Pairwise fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px
So why does this pairwise approach actually work better? Let me dive into it.
Why Pairwise Beats Pointwise Every Time
Okay so here’s the key insight: ranking is fundamentally a comparison problem, not a prediction problem.
When you use pairwise ranking, you’re training on pairs of items. For every query (like “best pizza near me”), you look at all possible pairs of results. If Item A should rank higher than Item B (maybe A has more stars, or more reviews, or whatever your ground truth is), you create a training example that says: “The model should score A higher than B.”
The loss function doesn’t care what the actual scores are. It only cares about the relative ordering. If the model predicts A at 2.1 and B at 1.8, great—A is ranked higher. If it predicts A at 0.01 and B at -0.5, also great—same ordering.
This has some pretty wild implications:
- You’re immune to score calibration issues (the model can be systematically biased toward certain categories and it doesn’t matter).
- You’re directly optimizing for what you actually care about (rank order, not score accuracy).
- And you can handle inconsistent labeling better (if different annotators use different scales, pairwise comparisons are more consistent than absolute ratings).
But here’s where it gets interesting: the pairwise loss function has to somehow convert these comparisons into gradients that gradient boosting can use. And that’s where LambdaRank comes in.
The whole pipeline flows like this:
- You start with a query
- Generate all possible pairs
- Compute lambda gradients for each pair (weighted by NDCG impact)
- Calculate Hessians for curvature information
and then LightGBM builds trees using those gradients and hessians to learn better ranking scores.
best pizza"] --> B["Pairs:
A vs B, A vs C..."] B --> C["Lambda:
λ = -σ/1+exp∆s"] C --> D["Weight
by ∆NDCG"] D --> E["Calc
Hessian"] E --> F["Build tree:
G²/H+λ"] F --> G["Score &
rank"] style A fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style B fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style C fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style D fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style E fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style F fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style G fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937
Notice how it’s a straight shot from query to final ranking, with each step feeding into the next.
Now let’s dig into the actual mathematics powering this whole system.
The Math That Makes LambdaRank Actually Work
So LambdaRank is basically the algorithm that figured out how to do pairwise ranking with gradient boosting. And the key trick is this:
instead of having a loss function that directly compares scores, you create “lambda” gradients that push pairs of items in the right direction.
For a pair of items $(i, j)$ where item $i$ should rank higher than item $j$, you compute:
\[\lambda_{ij} = \frac{-\sigma}{1 + e^{\sigma(s_i - s_j)}} \cdot |\Delta \text{NDCG}_{ij}|\]Let me unpack this because it looks scarier than it is.
The first part—that fraction with the exponential is basically a sigmoid function measuring how wrong your current ranking is. If $s_i$ (score for item $i$) is way higher than $s_j$ (score for item $j$), the exponential term gets huge, and the whole thing approaches zero. Translation: “You already got this pair right, no need to push harder.”
But if $s_i$ is lower than $s_j$, that denominator gets small, and lambda gets large. Translation: “You got this pair backwards, here’s a big gradient to fix it.”
The second part—$|\Delta \text{NDCG}_{ij}|$—is where LambdaRank gets clever.
NDCG (Normalized Discounted Cumulative Gain) is a ranking metric that cares more about getting the top results right than the bottom ones. By weighting the lambda gradient by how much swapping items $i$ and $j$ would change NDCG, you make the algorithm focus on the pairs that actually matter for ranking quality.
Here’s a concrete example:
- Imagine you have three restaurants ranked [A, B, C] but the correct order should be [A, C, B].
- Swapping B and C (positions 2 and 3) barely affects NDCG because they’re both lower in the ranking.
- If your model incorrectly ranks them [B, A, C], swapping B and A (positions 1 and 2) massively hurts NDCG because the top position is super important.
So LambdaRank assigns a huge gradient to the B-vs-A pair and a tiny gradient to the B-vs-C pair. This means the model focuses its learning on getting the top results right, which is exactly what you want in a ranking system.
And this is where LightGBM’s implementation gets really interesting—because it doesn’t just use first-order gradients (the lambdas). It also computes second-order derivatives (Hessians) to get better splits.
All good until here.
But what if you’re not just optimizing for one metric? What if you need to balance multiple objectives at once?
Multi-Objective Ranking: When You Want Everything
But think, what if you don’t just care about ranking accuracy? What if you want to optimize for multiple objectives at once?
This happens all the time in real systems.
Maybe you’re ranking products in an e-commerce site and you want to optimize for both relevance AND diversity. Or maybe you’re ranking ads and you care about click-through rate (CTR) AND revenue. Or maybe you’re building a recommendation system and you want high engagement AND long-term user satisfaction.
The standard approach is to combine your objectives into a single weighted loss:
\[L_{\text{total}} = \alpha \cdot L_{\text{NDCG}} + \beta \cdot L_{\text{diversity}} + \gamma \cdot L_{\text{recency}}\]You pick weights ($\alpha$, $\beta$, $\gamma$) that reflect your priorities, and boom—you’ve got a single objective to optimize. LightGBM’s gradient boosting machinery doesn’t know the difference. It just sees gradients and Hessians and builds trees.
Choosing those weights is an art form. Set $\alpha$ too high and you get super-relevant results that are all the same. Set $\beta$ too high and you get diverse garbage.
This is where Pareto optimization comes in. Instead of picking one magic combination of weights, you train multiple models with different weight configurations and look at the Pareto frontier—the set of solutions where you can’t improve one objective without hurting another.
Ranking
accuracy"] B["Diversity:
Result
variety"] end subgraph Loss["Combined Loss Function"] C["L = α·NDCG_loss
+ 1-α·Diversity_loss"] end subgraph Models["Train Multiple Models"] D1["α=1.0:
Pure NDCG"] D2["α=0.7:
Balanced"] D3["α=0.3:
More diversity"] end subgraph Pareto["Pick Best Tradeoff"] E["Evaluate on
real metrics"] F["Choose α that
fits product goals"] end A --> C B --> C C --> D1 C --> D2 C --> D3 D1 --> E D2 --> E D3 --> E E --> F style A fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style B fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style C fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style D1 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style D2 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style D3 fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style E fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style F fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style Objectives fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px style Loss fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px style Models fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px style Pareto fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px
In the process shown above, you’re essentially exploring the spectrum from pure accuracy (α=1.0) to balanced diversity (lower α values).
And the cool part? Because LightGBM’s pairwise ranking is so fast (we’re talking seconds to minutes even on large datasets), you can actually explore this Pareto frontier without waiting days for training.
The Hessian Secret Weapon
Okay so here’s a detail that most tutorials skip but is actually the reason LightGBM is fast and accurate: second-order optimization with Hessians.
Remember how gradient boosting works?
- You fit a tree to the negative gradient of your loss function.
- That gradient tells you the direction to move.
But it doesn’t tell you how far to move or how confident you should be about that direction.
That’s what the Hessian (second derivative) gives you.
It’s basically the curvature of the loss function. High curvature means the loss changes quickly—small movements matter a lot. Low curvature means the loss is flat—you need to move further to make a difference.
For pairwise ranking, the Hessian for each item ends up being:
\[h_i = \sum_{j: i \neq j} \lambda_{ij} \cdot \sigma \cdot e^{\sigma(s_i - s_j)} / (1 + e^{\sigma(s_i - s_j)})^2\]This looks gnarly, but the intuition is simple: it’s summing up how sensitive your ranking is to changes in item $i$’s score, weighted by all the pairs involving item $i$.
When LightGBM builds a tree, it uses both gradients and Hessians to compute the gain from each split. The formula for gain is:
\[\text{Gain} = \frac{1}{2} \left[ \frac{G_L^2}{H_L + \lambda} + \frac{G_R^2}{H_R + \lambda} - \frac{(G_L + G_R)^2}{H_L + H_R + \lambda} \right]\]Where $G_L$ and $G_R$ are the sum of gradients in the left and right child nodes, $H_L$ and $H_R$ are the sum of Hessians, and $\lambda$ is a regularization term.
Notice how the Hessian appears in the denominator? That’s what makes this second-order optimization.
If the Hessian is large (high curvature), the gain is discounted—the algorithm is more conservative. If the Hessian is small (flat loss landscape), the gain is amplified—the algorithm is more aggressive.
This is why LightGBM converges faster than algorithms that only use first-order gradients. It’s literally using more information about the loss landscape to make smarter split decisions.
The split decision process groups items by their gradients and Hessians, tries different splits (like “price < $50”), calculates the gain using both gradient and Hessian information, and keeps the split if the gain is high enough.
gradients G"] B["Items with
Hessians H"] end subgraph Split["Try Split: price < $50"] C["Left: G_L, H_L"] D["Right: G_R, H_R"] end subgraph Gain["Calculate Gain"] E["Gain = ½ * G_L²/H_L
+ G_R²/H_R
- G_total²/H_total"] end A --> C A --> D B --> C B --> D C --> E D --> E E --> F{"High
gain?"} F -->|Yes| G["Keep split"] F -->|No| H["Try different
feature"] style A fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style B fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style C fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style D fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style E fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style F fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style G fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style H fill:#FFFFFF,stroke:#9CA3AF,stroke-width:2px,color:#1F2937 style Input fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px style Split fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px style Gain fill:#F3F4F6,stroke:#9CA3AF,stroke-width:2px
Notice how the Hessian appears in the denominator of the gain formula, making the algorithm more conservative when the loss landscape has high curvature.
Alright, enough theory. Let’s see how you actually implement this in LightGBM.
Making It Real: Query Groups and Implementation
Alright, so how do you actually implement this in LightGBM? The key concept is query groups.
In ranking problems, your data isn’t just a flat list of items. It’s organized into queries, where each query has multiple items that need to be ranked relative to each other. Like “best pizza near me” returns 20 restaurants, “cheap laptops” returns 50 products, etc.
LightGBM needs to know which items belong to which query because pairwise comparisons only make sense within the same query. You don’t compare Restaurant A from Query 1 with Laptop B from Query 2—that doesn’t make sense.
So you provide two things:
- your training data (features and labels)
- query group array that says “the first 20 items belong to query 1, the next 50 belong to query 2,” etc.
Here’s a minimal code snippet showing the structure:
import lightgbm as lgb
# Your features and labels
X_train = ... # shape: (total_items, num_features)
y_train = ... # shape: (total_items) - labels
# Query groups: how many items per query
# e.g., [20, 50, 15] means query 1 has 20 items, query 2 has 50, query 3 has 15
query_groups = [20, 50, 15, ...] # sum should equal len(X_train)
# Create LightGBM dataset with query groups
train_data = lgb.Dataset(X_train, label=y_train, group=query_groups)
# Training parameters for LambdaRank
params = {
'objective': 'lambdarank',
'metric': 'ndcg',
'ndcg_eval_at': [10, 20],
'learning_rate': 0.05,
'num_leaves': 31,
'min_data_in_leaf': 20,
}
model = lgb.train(params, train_data, num_boost_round=100)
The magic happens in that 'objective': 'lambdarank' line. That tells LightGBM to compute pairwise lambda gradients and Hessians instead of treating this as a regression or classification problem.
And here’s the beautiful part: once trained, you just call model.predict(X_test) and you get scores. You group those scores by query and sort within each group. That’s your ranked results.
For multi-objective scenarios, you can use a custom objective function that combines multiple losses. Here’s how you’d implement a custom multi-objective loss that balances NDCG and diversity:
import numpy as np
def multi_objective_loss(preds, train_data):
"""
Custom objective combining ranking loss and diversity penalty
Returns gradients and Hessians for LightGBM
"""
labels = train_data.get_label()
group = train_data.get_group()
# Standard LambdaRank gradients (simplified)
grad = np.zeros_like(preds)
hess = np.zeros_like(preds)
alpha = 0.7 # Weight for ranking vs diversity
start = 0
for group_size in group:
# take a group
group_preds = preds[start:start + group_size]
group_labels = labels[start:start + group_size]
# calculate pairwise
for i in range(group_size):
for j in range(group_size):
if group_labels[i] > group_labels[j]:
delta = group_preds[i] - group_preds[j]
sig = 1.0 / (1.0 + np.exp(delta))
grad[start + i] += alpha * sig
grad[start + j] -= alpha * sig
hess[start + i] += alpha * sig * (1 - sig)
hess[start + j] += alpha * sig * (1 - sig)
# Diversity component (penalize similar predictions)
# We're measuring how "different" each document is from the average
diversity_penalty = (1 - alpha) * (group_preds - group_preds.mean())
grad[start:start + group_size] += diversity_penalty
hess[start:start + group_size] += (1 - alpha)
start += group_size
return grad, hess
# Use custom objective
model = lgb.train(
{'objective': multi_objective_loss, 'metric': 'ndcg'},
train_data,
num_boost_round=100
)
Let me break down what’s happening in that code because the gradient and Hessian calculations look like magic but they’re actually straightforward once you see the pattern.
For each query group,
- We loop through all pairs of items (i, j)
- Ff item i should rank higher than item j (because label[i] > label[j]), we calculate delta—the difference in their current predicted scores
- Then sig is a sigmoid function measuring how wrong this pair is
- If item i already scores higher than j, delta is positive, the sigmoid is small, and we barely update. But if item i scores LOWER than j (wrong order), delta is negative, sigmoid is large, and we apply big gradients.
The gradient updates are opposite for the two items: we push item i’s score UP (positive gradient) and item j’s score DOWN (negative gradient). That’s the += for i and -= for j. The Hessian is the second derivative of the sigmoid, which is sig times (1 - sig)—this captures the curvature of the loss and helps LightGBM make better split decisions.
The diversity component is simpler: we penalize predictions that are far from the group mean, which encourages the model to spread predictions out rather than clustering them. The gradient is just the deviation from the mean, and the Hessian is constant.
Finally, alpha (0.7) weights these two objectives: 70% ranking accuracy, 30% diversity. Adjust alpha to change the tradeoff.
LightGBM supports custom gradient and Hessian functions, so you can implement whatever multi-objective loss you dream up—just return the gradients and Hessians for your combined objective.
Summing it up
Real systems don’t optimize for one thing. They balance tradeoffs. And pairwise ranking gives you the framework to do that explicitly—train multiple models across the Pareto frontier, evaluate them on real metrics, pick the tradeoff that matches your product goals.
The reason pairwise ranking works so well isn’t because it’s mathematically sophisticated (though it is). It’s because it matches how ranking problems actually work in the real world.
When you’re building a search engine, you don’t care if your model predicts a 4.2 vs 4.1 for two restaurants. You care if it puts the better one first. When you’re recommending products, you don’t care about the absolute score. You care about the ordering.
And all of this is happening because of those lambda gradients—little derivative signals that push pairs of items in the right direction, weighted by how much those swaps matter for your ranking metric, refined by second-order curvature information to make smarter tree splits.
Did you find this post useful? I am curious to hear from you in comments below.

Comments